مدلهای مولد به سیستمهایی اطلاق میشود که قادر به ایجاد دادهها یا محتوای جدید مشابه دادههای واقعی هستند.





Topology Database یکی از اجزای اساسی در پروتکلهای مسیریابی Link-State مانند OSPF (Open Shortest Path First) و IS-IS (Intermediate System to Intermediate System) است که اطلاعات توپولوژی شبکه را ذخیره میکند. این پایگاه داده شامل اطلاعات دقیق در مورد وضعیت لینکها، روترها، و ارتباطات بین روترها در شبکه است. Topology Database به پروتکلهای مسیریابی کمک میکند تا تصمیمات بهینهتری در مورد انتخاب مسیرهای دادهها بگیرند و عملکرد بهتری در مسیریابی داشته باشند. در این مقاله، به بررسی مفهوم Topology Database، نحوه عملکرد آن، و نقش آن در پروتکلهای مسیریابی خواهیم پرداخت.
در پروتکلهای Link-State، هر روتر یک پایگاه داده وضعیت لینک (LSDB) دارد که اطلاعات توپولوژی شبکه را از سایر روترها دریافت و ذخیره میکند. این اطلاعات بهطور مداوم بهروزرسانی میشود و به روترها این امکان را میدهد که از بهترین مسیرهای ممکن برای ارسال بستههای داده استفاده کنند.
Topology Database یا پایگاه داده توپولوژی شبکه، یک ساختار داده است که اطلاعات دقیق در مورد وضعیت لینکها، روترها و ارتباطات بین روترها را در یک شبکه ذخیره میکند. این پایگاه داده معمولاً در پروتکلهای مسیریابی Link-State مانند OSPF و IS-IS استفاده میشود. در این پروتکلها، روترها اطلاعات وضعیت لینکها را با یکدیگر به اشتراک میگذارند و Topology Database بهعنوان پایگاهی برای ذخیره این اطلاعات عمل میکند.
هر روتر یک نسخه محلی از Topology Database خود را نگهداری میکند که شامل اطلاعات بهروز از شبکه است. این اطلاعات شامل وضعیت هر لینک (فعال یا غیرفعال)، هزینههای هر لینک، و اتصالهای بین روترهای مختلف است. هنگامی که توپولوژی شبکه تغییر میکند، اطلاعات موجود در پایگاه داده بهطور خودکار بهروزرسانی میشود.
عملکرد Topology Database بهطور عمده بر اساس تبادل اطلاعات وضعیت لینکها بین روترها است. در این پروسه، هر روتر اطلاعات وضعیت لینکهای خود را بهطور دورهای به سایر روترها ارسال میکند. این اطلاعات پس از دریافت، در پایگاه داده توپولوژی ذخیره میشود و بهطور خودکار جدولهای مسیریابی روتر بهروز میشود. مراحل عملکرد Topology Database به شرح زیر است:
Topology Database مزایای زیادی برای شبکهها و پروتکلهای مسیریابی دارد که بهویژه در شبکههای بزرگ و پیچیده اهمیت دارد. برخی از مزایای آن عبارتند از:
با وجود مزایای زیاد، Topology Database نیز معایب خاص خود را دارد که باید در نظر گرفته شوند. برخی از معایب آن عبارتند از:
Topology Database در پروتکلهای مسیریابی Link-State مانند OSPF و IS-IS کاربرد دارد. برخی از کاربردهای اصلی آن عبارتند از:
Topology Database یکی از اجزای اساسی پروتکلهای مسیریابی Link-State مانند OSPF است که اطلاعات دقیق در مورد وضعیت لینکها و توپولوژی شبکه را ذخیره میکند. این پایگاه داده به پروتکلهای مسیریابی کمک میکند تا بهترین مسیرها را برای ارسال دادهها انتخاب کنند و از بهروزرسانیهای دقیق توپولوژی شبکه بهرهبرداری کنند. با وجود مزایای زیادی که Topology Database دارد، مانند دقت بالا و مقیاسپذیری، این ویژگی نیز معایبی مانند مصرف منابع بیشتر و پیچیدگی در پیادهسازی دارد. برای درک بهتر نحوه عملکرد Topology Database و بهینهسازی استفاده از آن در شبکه، میتوانید به سایت saeidsafaei.ir مراجعه کنید.
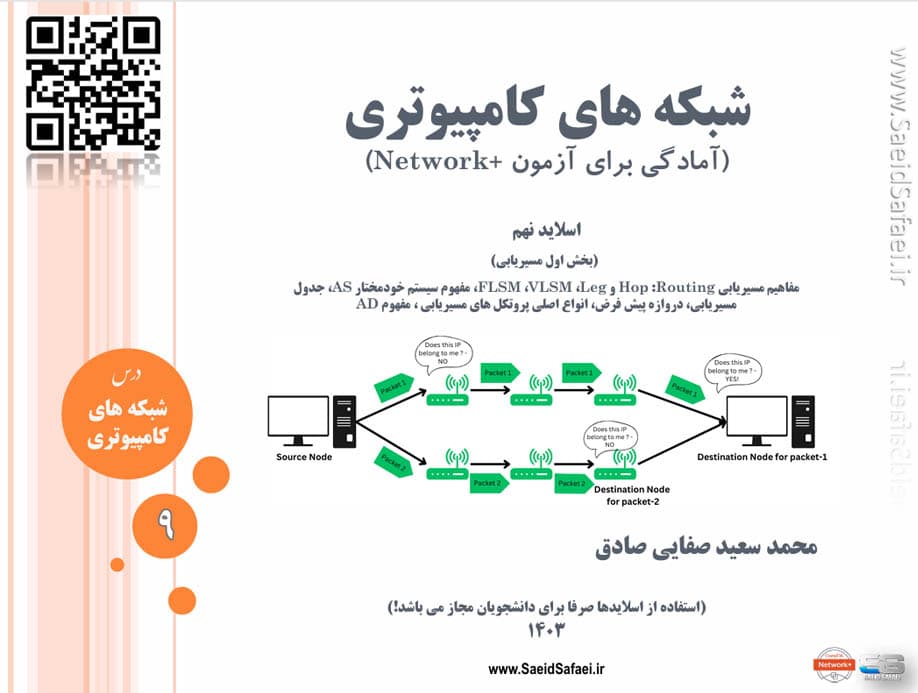
در این جلسه (بخش اول مسیریابی)، مفاهیم پایهای مسیریابی (Routing) مانند Hop، InterVLAN و Leg بررسی میشوند. سپس، تکنیکهای VLSM (Variable Length Subnet Mask) و FLSM (Fixed Length Subnet Mask) توضیح داده میشوند. همچنین، مفهوم سیستم خودمختار (AS) و اهمیت آن در مسیریابی، ساختار جدول مسیریابی و نقش دروازه پیشفرض بررسی خواهد شد. در نهایت، انواع کلاسهای پروتکلهای مسیریابی معرفی و ویژگیهای آنها مورد بحث قرار میگیرد. هدف این جلسه، درک اصول مسیریابی و نحوه مدیریت مسیرها در شبکههای پیچیده است.
مدلهای مولد به سیستمهایی اطلاق میشود که قادر به ایجاد دادهها یا محتوای جدید مشابه دادههای واقعی هستند.
روش دسترسی به رسانه که در آن زمانبندی برای تقسیم دسترسی به رسانه بین دستگاهها استفاده میشود، هر دستگاه یک بازه زمانی برای ارسال داده دارد.
عملگر افزایش پس از عملگر ()++ است که ابتدا مقدار متغیر را میخواند و سپس آن را افزایش میدهد.
درخت دودویی نوعی درخت است که در هر گره آن حداکثر دو فرزند وجود دارد.
محاسبه یک فرآیند عددی است که معمولاً با استفاده از ابزارهای محاسباتی مانند ماشین حساب یا نرمافزارهای خاص انجام میشود. محاسبات معمولاً برای تجزیه و تحلیل دادههای عددی انجام میگیرد.
دیسکهای مغناطیسی که معمولاً به عنوان حافظههای ثانویه (مثل هارد دیسکها) برای ذخیرهسازی دائمی دادهها استفاده میشوند.
اضافهبارگذاری تابع به معنای تعریف چندین تابع با نام یکسان اما با پارامترهای مختلف است. این ویژگی به توابع این امکان را میدهد که با انواع مختلف ورودی کار کنند.
مدلی سادهتر از OSI که چهار لایه دارد و بهطور گسترده برای ارتباطات اینترنتی استفاده میشود.
یال یک اتصال بین دو گره در گراف است که ارتباط یا وابستگی بین آنها را نشان میدهد.
مجموعهای از دادهها است که به صورت ساختار یافته ذخیره شده و به راحتی میتوان به آنها دسترسی داشت.
بخشهایی از کد هستند که یک وظیفه خاص را انجام میدهند و میتوانند در نقاط مختلف برنامه فراخوانی شوند.
نگهداری پیشبینی در صنعت به استفاده از دادههای تاریخچهای و الگوریتمها برای پیشبینی خرابی و نیاز به تعمیر در تجهیزات صنعتی اشاره دارد.
یادگیری ماشین توزیعشده به روشهای یادگیری ماشین اطلاق میشود که از چندین گره محاسباتی برای پردازش دادهها بهطور همزمان استفاده میکنند.
GraphQL یک زبان پرسوجو است که برای دریافت دادهها از یک API استفاده میشود و در مقایسه با REST، انعطافپذیری بیشتری دارد.
حالت انتقال داده دو طرفه اما نوبتی که در آن تنها یکی از دستگاهها در هر زمان میتواند دادهها را ارسال یا دریافت کند.
نویز ناشی از حرکت الکترونها در مواد نیمههادی یا فلزات که در اثر حرارت ایجاد میشود.
ساخت دیجیتال به استفاده از فناوریهای دیجیتال برای طراحی و ساخت محصولات فیزیکی و مدلهای پیچیده اطلاق میشود.
روش دسترسی به رسانه که در آن منابع فرکانسی بهطور ثابت بین دستگاهها تقسیم میشود.
فردی که مسئول راهاندازی، پیکربندی و نگهداری شبکههای کامپیوتری است.
واحد کنترل است که مسئول هدایت و کنترل سایر بخشهای پردازنده است و عملیاتها را طبق دستورالعملها انجام میدهد.
آندر فلو زمانی رخ میدهد که مقدار عددی مورد نظر از حداقل مقدار قابل نمایش در سیستم کمتر باشد.
محاسبات با عملکرد بالا به استفاده از قدرت پردازشی پیشرفته برای حل مسائل پیچیده و پردازش دادههای بسیار بزرگ اطلاق میشود.
پردازش دادهها در زمان واقعی به تحلیل و پردازش دادهها بلافاصله پس از دریافت آنها گفته میشود، بدون نیاز به ذخیرهسازی طولانیمدت.
این مفهوم در رمزنگاری به معنای اثبات صحت یک ادعا بدون فاش کردن اطلاعات اضافی است. این برای حفظ حریم خصوصی در تراکنشهای دیجیتال و قراردادهای هوشمند کاربرد دارد.
توزیع کلید کوانتومی (QKD) به استفاده از اصول فیزیک کوانتومی برای تولید و توزیع کلیدهای رمزنگاری بهصورت ایمن اشاره دارد.
سیگنال دیجیتال یک نوع سیگنال است که در آن اطلاعات به صورت دادههای دیجیتال (0 و 1) منتقل میشوند.
پروتکلی که ترکیبی از ویژگیهای Distance Vector و Link State است و از نقاط قوت هر دو استفاده میکند.
دستگاههای ورودی مانند موس و کیبورد که اطلاعات را به کامپیوتر وارد میکنند.
سازمانهای خودمختار غیرمتمرکز (DAO) به سازمانهایی اطلاق میشود که بدون نیاز به مدیریت متمرکز با استفاده از قراردادهای هوشمند عمل میکنند.
یادگیری تقویتی عمیق به استفاده از الگوریتمهای یادگیری برای بهبود تصمیمگیری سیستمها در محیطهای پیچیده گفته میشود.
در همتنیدگی کوانتومی به پدیدهای در فیزیک کوانتومی اطلاق میشود که در آن ذرات میتوانند بهطور همزمان در دو مکان متفاوت قرار داشته باشند.
یک آسیبپذیری که به محض انتشار یک نرمافزار مورد سوء استفاده قرار میگیرد و اطلاعات یا سیستمها را به خطر میاندازد.
بازیهای واقعیت افزوده (AR) به بازیهایی گفته میشود که دنیای واقعی را با عناصر دیجیتال ترکیب میکنند.
متغیر در برنامهنویسی به فضایی در حافظه گفته میشود که برای ذخیره دادهها استفاده میشود. این دادهها میتوانند در طول اجرای برنامه تغییر کنند.
مهندسی زیستشناسی مصنوعی به طراحی و مهندسی موجودات یا سیستمهای مصنوعی با ویژگیهای بیولوژیکی گفته میشود.
